 题目内容
(请给出正确答案)
题目内容
(请给出正确答案)
[主观题]
用一组有n个观测值的样本估计模型Yi=β1X1i+β2X2i+μi后,在显著性水平α下对β1的显著性作t检验,则β1
显著地不等于零的条件是其统计量大于等于()。
A.tα(n-2-1)
B.tα(n-2)
C.tα/2(n-2-1)
D.tα/2(n-2)
查看答案

 如果结果不匹配,请 联系老师 获取答案
题目内容
(请给出正确答案)
如果结果不匹配,请 联系老师 获取答案
题目内容
(请给出正确答案)
A.tα(n-2-1)
B.tα(n-2)
C.tα/2(n-2-1)
D.tα/2(n-2)
如果结果不匹配,请 联系老师 获取答案
 更多“用一组有n个观测值的样本估计模型Yi=β1X1i+β2X2i…”相关的问题
更多“用一组有n个观测值的样本估计模型Yi=β1X1i+β2X2i…”相关的问题
A.CE(ui)=0
B.Var(ui)=σ2
C.ov(ui,uj)=0
D.ui服从正态分布
E.X为非随机变量,与随机误差项ui不相关
本题使用LOANAPP.RAW中的数据。
(i)有多少个观测的obrat>40,即其他债务负担超过其总收入的40%?
(ii)在计算机习题C7.8中,去掉o brat 40的观测,重新估计第(iii)部分中的模型。white的系数估计值和t统计量将会怎样?
(iii)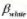 看起来对所使用的样本过度敏感吗?
看起来对所使用的样本过度敏感吗?
总体X的一组容量为5的样本的观测值为8,2,5,3,7.求样本均值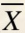 ,样本方差s2,样本二阶中心矩b2及经验分布函数F5(x).
,样本方差s2,样本二阶中心矩b2及经验分布函数F5(x).
设(X1,X2,…,Xn)为来自正态总体N(0,σ2)的样本,
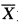 为其样本均值,记 Yi=Xi—
为其样本均值,记 Yi=Xi—
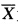 ,i=1,2,…,n. (1)求Yi的方差D(Yi),i=1,2,…,n; (2)求Y1与Yn的协方差Cov(Y1,Yn); (3)若c(Y1+Yn)2是σ2的无偏估计,求常数c.
,i=1,2,…,n. (1)求Yi的方差D(Yi),i=1,2,…,n; (2)求Y1与Yn的协方差Cov(Y1,Yn); (3)若c(Y1+Yn)2是σ2的无偏估计,求常数c.
A.样本容量太小
B.估计量缺乏有效性
C.选择的估计量有偏
D.抽取样本时破坏了随机性
A.MLE中加入了模型参数本身的概率分布
B.MLE认为模型参数本身概率是不均匀的
C.MLE体现了贝叶斯认为参数也是随机变量的观点
D.MLE是指找出一组参数,使得模型产生出观测数据的概率最大
A.Logistic回归本质上是一种根据样本对权值进行极大似然估计的方法,用先验概率的乘积代替后验概率
B.Logistic回归的输出就是样本属于正类别的几率
C.SVM的目标是找到使得训练数据尽可能分开且分类间隔最大的超平面,属于结构风险最小化
D.SVM可以通过正则化系数控制模型的复杂度,避免过拟合
A.不存在一阶自相关
B.存在正的一阶自相关
C.存在负的一阶自
D.无法确定
对参数的一种区间估计及一组样本观察值(x1,x2,…,xn)来说,下列结论中正确的是().
A.置信度越大,对参数取值范围估计越准确;
B.置信度越大,置信区间越短;
C.置信度大小与置信区间的长度无关.
















