 题目内容
(请给出正确答案)
题目内容
(请给出正确答案)
[主观题]
我们利用CEOSAL1.RAW中的数据估计了如下方程 这个方程使得roe对log(salary)具有边际递减的影
我们利用CEOSAL1.RAW中的数据估计了如下方程

这个方程使得roe对log(salary)具有边际递减的影响。这种一般性是必然的吗?解释为什么。
查看答案

 如果结果不匹配,请 联系老师 获取答案
题目内容
(请给出正确答案)
如果结果不匹配,请 联系老师 获取答案
题目内容
(请给出正确答案)
我们利用CEOSAL1.RAW中的数据估计了如下方程
这个方程使得roe对log(salary)具有边际递减的影响。这种一般性是必然的吗?解释为什么。
如果结果不匹配,请 联系老师 获取答案
 更多“我们利用CEOSAL1.RAW中的数据估计了如下方程 这个方…”相关的问题
更多“我们利用CEOSAL1.RAW中的数据估计了如下方程 这个方…”相关的问题
利用PHILLIPS.RAW中的数据。
(i)用直至1997年的数据估计教材(18.48)和(18.49)中的模型。参数估计值与教材(18.48)和教材(18.49)中的结果相比有很大不同吗?
(ii)用新方程预测unem1998,小数点后保留两位数。哪个方程预测得更好?
(ii)我们在正文中讨论过,用教材(18.49)预测unem1998为4.90.把它与利用直至1997年的数据得到的预测相比较。多用一年数据求得的参数估计值能给出更好的预测吗?
(iv)用教材(18.48)中估计的模型求出unem的提前两期预测值。即利用α=1.572,p=0.732,h=2时的教材方程(18.55)预测unem与把unem1997=4.9代入教材(18.48)所得到的提前一期预测值相比,哪一个更好?
在教材例11.6中,我们估计了一个一阶差分形式的有限分布滞后模型:
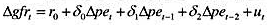
利用FERTIL3.RAW中的数据来检验误差中是否存在AR(1)序列相关。
在例11.6中,我们估计了一个一阶差分形式的有限分布滞后模型:
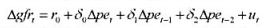
利用FERTIL 3.RAW中的数据来检验误差中是否存在AR(1) 序列相关。
A.生活中有效搜集和科学分析数据,可以发现事物的牲和规律,利用Excel处理数据可以快速帮助人们作出理性的决策
B.电子表格具有好操作,易传播的特点
C.电子表格数据一旦输入,无法再次修改
D.为防止他人恶意修改数据,我们可以为Excel工作表进行加密
(i)利用PHILLIPS.RAW中的数据估计方程(10.2),并以通常格式报告结果。你现在有多少观测数据?
(ii)将第(i)部分的估计值与方程(10.14)中的估计值进行比较。特别是,额外增加的年份对于得到通货膨胀与失业交替关系的估计值是否有帮助?请加以解释。
(iii)现在仅用1997~2003年的数据进行回归。这些估计值与方程(10.14)中的估计值有何不同?利用最近7年数据所得到的估计值足以得到某些肯定的结论吗?请加以解释。
(iv)考虑这样的一个简单回归背景:我们从n个时间序列观测开始,然后把它们分成早期和晚期两个部分。在第一个时期我们有n1个观测,在第二个时期我们有n2个观测。根据本题前面部分的分析评价如下命题:“一般而言,利用所有n次观测得到的斜率估计值大致等于利用早期子样本和晚期子样本所得到的斜率估计值的加权平均,权重分别为n1/n和n2/n。”
利用PHILLIPS.RAW中的数据,但只到1996年。
(i)在教材例11.5中,我们假定自然失业率是常数。在另一种形式的附加预期的菲利普斯曲线中,自然失业率受历史失业水平的影响。最简单的情况是,t时期的自然失业率与unemt-1,相等。如果我们假定适应性预期,便得到一个通货膨胀和失业率都是一阶差分形式的菲利普斯曲线: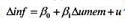 估计这个模型,以常见格式报告结果,并讨论β1的符号、大小和统计显著性。
估计这个模型,以常见格式报告结果,并讨论β1的符号、大小和统计显著性。
(ii)教材(11.19)和第(i)部分中的模型,哪一个对数据拟合得更好?说明理由。
在例9.1中,我们narr86在的一个线性模型中增加二次项pcrv2、ptime86²和inc 862。
(i)利用CRIME L RAW中的数据, 在例17.3的泊松回归中同样增加这些项。
(ii)根据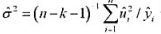 估计 。数据存在过度散布的证据吗?该如何调整泊松极大似然估计标准误?
估计 。数据存在过度散布的证据吗?该如何调整泊松极大似然估计标准误?
(iii)利用第(i)部分和第(ii)部分的结论及教材表17.3,计算这三个平方项联合显著性的准似然比统计量。你得到什么结论?
利用HPRICE1.RAW中的数据。
(i)估计模型
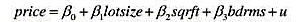
并按通常的格式报告你的结果,包括回归标准误。当我们代入lotsize=10000,sqrft=2300和bdrms=4时,求出预测价格,将这个价格四舍五入到美元。
(ii)做一个回归,使你能得到第(i)部分中预测值的一个95%的置信区间。注意,由于四舍五入的误差,你的预测将多少有些不同。
(iii)令price0为具有第(i)部分和第(ii)部分所述特征的住房的未知未来售价。求出price0的一个95%的置信区间,并对这个置信区间的宽度进行评论。
(i)利用表13-1中同样的变量估计kids的一个泊松回归模型。解释y82的系数。
(ii)保持其他因素不变,黑人妇女和非黑人妇女在生育上的估计百分数差异是多少?
(iii)求σ。有过度散布和散布不足的证据吗?
(iv)计算泊松回归中的拟合值和作为kidsi和kidsi之相关系数平方的R2。并与线性回归模型中的R2相比较。
















