 题目内容
(请给出正确答案)
题目内容
(请给出正确答案)
[判断题]
一元线性回归中,估计标准误差反映了实际值在估计回归直线周围的分散情况,标准误差越大,则就越分散;标准误差越小,则就越集中()
查看答案

 如果结果不匹配,请 联系老师 获取答案
题目内容
(请给出正确答案)
如果结果不匹配,请 联系老师 获取答案
如果结果不匹配,请 联系老师 获取答案
题目内容
(请给出正确答案)
如果结果不匹配,请 联系老师 获取答案
 更多“一元线性回归中,估计标准误差反映了实际值在估计回归直线周围的…”相关的问题
更多“一元线性回归中,估计标准误差反映了实际值在估计回归直线周围的…”相关的问题
(i)利用表13-1中同样的变量估计kids的一个泊松回归模型。解释y82的系数。
(ii)保持其他因素不变,黑人妇女和非黑人妇女在生育上的估计百分数差异是多少?
(iii)求σ。有过度散布和散布不足的证据吗?
(iv)计算泊松回归中的拟合值和作为kidsi和kidsi之相关系数平方的R2。并与线性回归模型中的R2相比较。
用单位平均抽样来估计存货价值,内部审计师得到了下列结果:
预计存货价值 $3000000
置信水平 95%
置信区间 $2800000-$3200000
标准差(标准离差/样本量的平方根) $100000
Z值(大约) 2.0
精确度 $200000
存货的账面值约为 $3075000
标准误差为 $100000
反映了:
A.在样本误差的基础上得出的预计总体误差
B.样本的平均误差率
C.样本项目金额数的变化程度
D.内部审计师可接受的总体误差
在例9.1中,我们narr86在的一个线性模型中增加二次项pcrv2、ptime86²和inc 862。
(i)利用CRIME L RAW中的数据, 在例17.3的泊松回归中同样增加这些项。
(ii)根据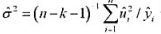 估计 。数据存在过度散布的证据吗?该如何调整泊松极大似然估计标准误?
估计 。数据存在过度散布的证据吗?该如何调整泊松极大似然估计标准误?
(iii)利用第(i)部分和第(ii)部分的结论及教材表17.3,计算这三个平方项联合显著性的准似然比统计量。你得到什么结论?
利用NYSE.RAW中的数据。
(i)估计教材方程(12.47)中的模型并求OLS残差平方。求u2t在整个样本中的平均值、最小值和最大值。
(ii)利用OLS残差平方估计如下的异方差性模型
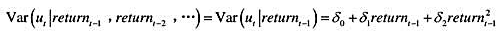
报告估计系数、标准误、R²和调整R²。
(ii)将条件方差描述成滞后return-1的函数。方差在return_,取何值时最小?这个方差是多少?
(iii)为了预测动态方差,第(ii)部分的模型得到了负的方差估计值吗?
(v)第(ii)部分中的模型拟合效果比教材例12.9中的ARCH(1)模型更好还是更差?请解释。
(vi)在教材方程(12.51)的ARCH(1)回归中添加二阶滞后ut-22。这个滞后看起来重要吗?这个ARCH(2)模型比第(ii)部分中的模型拟合得更好吗?
A.如果使用横断面数据进行回归分析会使r2的值上升。
B.回归分析对估计利息收入不再适用。
C.一些没有包括在模型中的新的因素引起了收入的变化。
D.线性回归分析会提高模型的可信度。
利用APPLE.RAW来验证6.3节中的一些命题。
(i)做ecolbs对ecoprc和reprc的回归,并以通常的格式报告结论,包括R²和调整R²。解释价格变量的系数,并评论它们的符号和大小。
(ii)价格变量统计显著吗?报告个别t检验的P值。
(iii)ecolbs拟合值的范围是什么?样本报告ecolbs=0比例是什么?请评论。
(iv)你认为价格变量很好地解释了ecolbs中的变异吗?请解释。
(V)在第(i)部分的回归中增加变量faminc,hhsize(家庭规模),educ和age。求它们联合显著的P值。你得到什么结论?
A.一元线性回归预测是回归预测的基础,预测对象只受一个主要因素影响
B.判定一个线性回归方程的拟合程度的优劣称为模型的显著性检验,通常用的检验法是相关系数检验法
C.相关系数等于回归平方和在总平方和中所占的比率,即回归方程所能解释的因变量变异性的百分比,是一元回归模型中用来衡量两个变量之间相关程度的判定指标
D.如果相关系数r=0,表示所有的观测值全部落在回归直线上;如果r=1,则表示自变量与因变量无线性关系
















