

 如果结果不匹配,请
如果结果不匹配,请 
 更多“为什么在ava中使用RunnableInterface?”相关的问题
更多“为什么在ava中使用RunnableInterface?”相关的问题
第4题
在药物静脉注射时,需将所注射药物稀释在5%的葡萄糖溶液或0.9%的生理盐水中,请用溶液依数性知识计算说明为什么使用这两种浓度的溶液。(提示:细胞正常渗透压值为770 kPa左右;NaCl和葡萄糖分子量分别为58.5、180.0 g/mol)
第8题
用到CONSUMP.RAW中的数据。 (i)在教材例16.7中,用教材15.5节的方法检验在估计教材(16.35)时的
用到CONSUMP.RAW中的数据。 (i)在教材例16.7中,用教材15.5节的方法检验在估计教材(16.35)时的
点击查看答案
用到CONSUMP.RAW中的数据。
(i)在教材例16.7中,用教材15.5节的方法检验在估计教材(16.35)时的那个过度识别约束。你的结论是什么?
(ii)由于潜在的数据度量问题和信息滞后,坎贝尔和曼昆(CampbellandMankiw,1990)使用所有变量的二阶滞后值作为工具变量。只用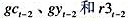 ,作为工具变量重新估计教材(16.35)。这些估计值与教材(16.36)中的那些估计值相比如何?
,作为工具变量重新估计教材(16.35)。这些估计值与教材(16.36)中的那些估计值相比如何?
(iii)将gy,对第(ii)部分的Ⅳ回归,并检验gy,与它们是否充分相关。这一点为什么重要?
第10题
本题利用MATHPNL.RAW中的数据。类似计算机习题C13.11中的一阶差分分析, 这里将做一个固定效应分
析。我们关心的模型是:
点击查看答案
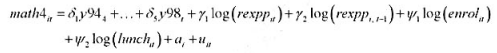
其中,因为滞后支出变量,第一个可用年份(基年)是1993年。
(i)用混合OLS估计模型, 并报告通常的标准误。为使得ai的期望值可以非零, 你应该与年度虚拟变量一起包含一个截距项。支出变量的估计效应是什么?求OLS残差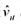 。
。
(ii)lunchit系数的符号在意料之中吗?解释系数的大小。你认为学区的贫穷率对考试通过率有很大的影响吗?
(iii)利用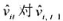 的回归计算AR(1)序列相关的一个检验。你应该在回归中使用1994~1998年的数据。验证存在很强的正序列相关,并讨论为什么。
的回归计算AR(1)序列相关的一个检验。你应该在回归中使用1994~1998年的数据。验证存在很强的正序列相关,并讨论为什么。
(iv)现在用固定效应法估计方程。滞后的支出变量仍显著吗?
(v)你为什么认为在固定效应估计中,注册学生人数和午餐项目变量不是联合显著的?
















