 题目内容
(请给出正确答案)
题目内容
(请给出正确答案)
[判断题]
如果我使用数据集的全部特征并且能够达到100%的准确率,但在测试集上仅能达到70%左右,这说明模型欠拟合。()
查看答案

 如果结果不匹配,请 联系老师 获取答案
题目内容
(请给出正确答案)
如果结果不匹配,请 联系老师 获取答案
如果结果不匹配,请 联系老师 获取答案
题目内容
(请给出正确答案)
如果结果不匹配,请 联系老师 获取答案
 更多“如果我使用数据集的全部特征并且能够达到100%的准确率,但在…”相关的问题
更多“如果我使用数据集的全部特征并且能够达到100%的准确率,但在…”相关的问题
A.使用前向特征选择方法
B.使用后向特征排除方法
C.我们先把所有特征都使用,去训练一个模型,得到测试集上的表现.然后我们去掉一个特征,再去训练,用交叉验证看看测试集上的表现.如果表现比原来还要好,我们可以去除这个特征
D.查看相关性表,去除相关性最高的一些特征
A.!ip.addr==10.2.2.2 && !tcp.flags.syn==1
B.!ip.addr==10.2.2.2 && tcp.flags.syn!=1
C.ip.addr!=10.2.2.2 && !tcp.flags.syn==1
D.ip.addr==10.2.2.2 && tcp.flags.syn!=1
A.对训练集随机采样,在随机采样的数据上建立模型
B.尝试使用在线机器学习算法
C.使用PCA算法减少特征维度
假设某公司销售业务中使用的订单格式如下:公司的业务规定:订单号是唯一的,每张订单对应一个订单号;一张订单可以订购多种产品,每一种产品可以在多个订单中出现;一张订单有一个客户,且一个客户可以有多张订单;每一个产品编号对应一种产品的品名和价格;每一个客户有一个确定的名称和电话号码。试根据上述表格和业务规则设计关系模式:R(订单号,订货日期,客户名称,客户电话,产品编号,品名,价格,数量)试回答下列问题:(1)出R的基本函数依赖集。(2)出R的候选码。(3)判断R最高可达到第几范式?为什么?(4)如果R不属于3NF,请将R分解成3NF模式集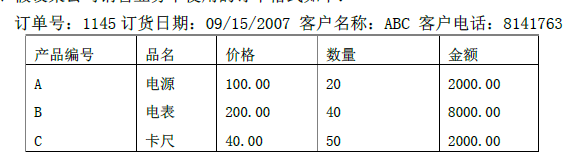
利用AIRFARE.RAW中的数据。我们的兴趣在于估计模型
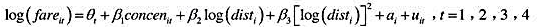
其中,θt意味着,我们容许每年的截距有所不同。
(i)用混合OLS估计上述方程,注意包含年度虚拟变量。若Δconcen=0.10,估计fare提高了多少个百分点?
(ii)的通常OLS的95%置信区间是什么?它为什么可能不太可靠?如果你有能计算充分稳健标准误的统计软件,求出β1的充分稳健的95%置信区间。与通常的置信区间相比较,并评论。
(iii)描述log(dist)的二次项出现的情况。特别是,dist取何值时,log(fare)和dit之间开始出现正向关系。[提示:首先计算log(dist)的转折点,然后取指数。]转折点出现在数据范围之外吗?
(iv)现在用随机效应法估计方程。β1的估计值有何变化?
(v)现在用固定效应法估计方程。β1的FE估计值是多少?它为何与RE估计值相当类似?(提示:RE估计的入是多少?)
(vi)指出由ai刻画的两个航线特征(除起降距离之外)。这些特征可能与concenit相关吗?
(vii)你相信航线更集中会提高飞机票价吗?最佳估计值是什么?
















