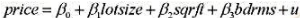题目内容
(请给出正确答案)
题目内容
(请给出正确答案)
[单选题]
当数据压入堆栈时SP的值减小,且当数据全部入栈后SP指向最后一个入栈数据的下一个存储单元,这种堆栈称为()。
A.满递增
B.满递减
C.空递增
D.空递减
查看答案

 如果结果不匹配,请 联系老师 获取答案
题目内容
(请给出正确答案)
如果结果不匹配,请 联系老师 获取答案
题目内容
(请给出正确答案)
A.满递增
B.满递减
C.空递增
D.空递减
如果结果不匹配,请 联系老师 获取答案
 更多“当数据压入堆栈时SP的值减小,且当数据全部入栈后SP指向最后…”相关的问题
更多“当数据压入堆栈时SP的值减小,且当数据全部入栈后SP指向最后…”相关的问题
问题描述;设S是正整数集合.S是一个无和集,当且仅当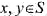 蕴含.对于任意正整数k,如果可将{1.2,...,k}划分为n个无和子集
蕴含.对于任意正整数k,如果可将{1.2,...,k}划分为n个无和子集 ,则称正整数k是n可分的.记F(n)=max{k|k是n可分的}.试设计一个算法,对任意给定的n,计算F(n)的值.
,则称正整数k是n可分的.记F(n)=max{k|k是n可分的}.试设计一个算法,对任意给定的n,计算F(n)的值.
算法设计:对任意给定的n,计算F(n)的值.
数据输入:由文件input.txt给出输入数据.第I行有1个正整数n.
结果输出:将计算的F(n)的值以及{1,2,F(n)}的一个n划分输出到文件output.txt.文件的第1行是F(n)的值.接下来的n行,每行是一个无和子集Si.


(2)从书中查出上述各碳酸盐的分解温度(CdCO3为345℃),与计算结果加以比较,并加以评价.
(3)各碳酸盐分解温度的实验值与由计算结果所得出的有关碳酸盐的分解温度的规律是否一致?并从离子半径、离子电荷、离子的电子构型等因素对上述规律加以说明.
(3)分解温度的实际值和计算值的规律是一致的.金属离子的半径越小,离子所带的电荷数越大,极化能力就越强,相应碳酸盐分解温度越低;金属离子电子构型为18e的极化能力比8e的强;而极化越大,相应的碳酸盐越易分解.
A.加大移动平均法的期数(加大n值)会使平滑波动效果更好,但使预测值对数据实际变动更不敏感
B.移动平均法进行预测能平滑掉需求的突然波动对预测结果的影响
C.简单移动平均和加权移动平均需要的数据量大,计算量非常大,当产品很多时计算工作繁重
D.移动平均值并不能总是很好地反映出趋势
A.在一个数据表中定义了外键后,数据库系统会保证插入外键中的每一个非空值都在被参照表当中作为主键出现
B.使用RESTRICT动作时,将待插入记录值的相应外键字段改成其所参照表中不存在的数据值,插入操作会被数据库拒绝
C.使用SETDEFAULT动作时,从所参照父表删除或更新行时,删除在参照子表中对应的该外键值对应行或者对该行外键做同样的修改
D.使用CASCADE动作时,当所参照父表中试图删除某行或对外键列某行数据值进行更新,参照子表中不做任何反应动作
本题利用HPRICE1.RAW中的数据。
(i)估计模型
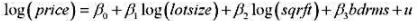
并以通常的OLS格式报告结论。
(ii)当lotsize=20000,scrft=2500和bdrms=4时,求出log(price) 的预测值。利用6.4节中的方法,在同样的解释变量值的情况下,求出price的预测值。
(iii)就解释price中的变异而言,决定你是偏好第(i)部分中的模型,还是偏好模型