 题目内容
(请给出正确答案)
题目内容
(请给出正确答案)
[多选题]
一个回归模型存在多重共线问题。在不损失过多信息的情况下,可如何处理()。
A.剔除所有的共线性变量
B.剔除共线性变量中的一个
C.通过计算方差膨胀因子(VarianceInflationFactor,VIF)来检查共线性程度,并采取相应措施
D.删除相关变量可能会有信息损失,我们可以不删除相关变量,而使用一些正则化方法来解决多重共线性问题,例如Ridge或Lasso回归
查看答案

 如果结果不匹配,请 联系老师 获取答案
题目内容
(请给出正确答案)
如果结果不匹配,请 联系老师 获取答案
题目内容
(请给出正确答案)
A.剔除所有的共线性变量
B.剔除共线性变量中的一个
C.通过计算方差膨胀因子(VarianceInflationFactor,VIF)来检查共线性程度,并采取相应措施
D.删除相关变量可能会有信息损失,我们可以不删除相关变量,而使用一些正则化方法来解决多重共线性问题,例如Ridge或Lasso回归
如果结果不匹配,请 联系老师 获取答案
 更多“一个回归模型存在多重共线问题。在不损失过多信息的情况下,可如…”相关的问题
更多“一个回归模型存在多重共线问题。在不损失过多信息的情况下,可如…”相关的问题
A.异方差
B.完全多重共线
C.遗漏变量偏差
D.虚拟变量陷阱
A.移除两个共线变量
B.不移除两个变量,而是移除一个
C.移除相关变量可能会导致信息损失,可以使用带罚项的回归模型(如ridge或lassoregression)
A.在严重多重共线性下,OLS估计量仍是最正确线性无偏估计量
B.多重共线性问题的实质是样本现象,因此可以通过增加样本信息得到改善
C.虽然多重共线性下,很难准确区分各个解释变量的单独影响,但可据此模型进展预测
D.如果回归模型存在严重的多重共线性,可不加分析地去掉某个解释变量从而消除多重共线性
A.千禧一代将以科技替代人工在线顾问
B.机器人投顾是一个全新的概念和商业模型
C.机器人投顾将进入高端市场并主要提供ETF资产
D.机器人投顾将对美国的财富管理市场产生冲击
E.财富管理市场现有公司将遭受损失
A.增加自变量后,模型包含的信息量增多,多重判定系数会随着自变量的增加而无限变大
B.增加自变量后,模型的预测误差会变小,从而减少残差平方和,此时回归平方和会变大
C.增加自变量后,各个自变量之前的相关关系更加紧密
D.增加自变量后,能使得所有自变量的系数显著
A.用横截面数据建立家庭消费支出对家庭收入水平的回归模型
B.用横截面数据建立产出对劳动和资本的回归模型
C.以凯恩斯的有效需求理论为根底构造宏观计量经济模型
D.以国民经济核算XX为根底构造宏观计量经济模型
E.以30年的时序数据建立某种商品的市场供需模型
本题利用NBASAL.RAW中的数据。
(i)估计一个线性回归模型,将单场得分与联赛中打球经历和位置(后卫、前锋或中锋)联系起来。包括打球经历的二次项形式,并将中锋作为基组。以通常的形式报告结果。
(ii)在第(i)部分中,你为什么不将所有三个位置虚拟变量包括进来?
(iii)保持经历不变,一个后卫的得分比一个中锋多吗?多多少?这个差异统计显著吗?
(iv)现在,将婚姻状况加入方程。保持位置和经历不变,已婚球员是否更高效(就单场得分来说)?
(v)加入婚姻状况和两个经历变量的交互项。在这个扩展的模型中,是否存在有力的证据表明婚姻状况影响单场得分?
(vi)使用单场助攻次数作为因变量估计(iv)中的模型。与(iv)的结果有明显的差异吗?请讨论。
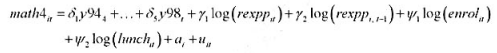
其中,因为滞后支出变量,第一个可用年份(基年)是1993年。
(i)用混合OLS估计模型, 并报告通常的标准误。为使得ai的期望值可以非零, 你应该与年度虚拟变量一起包含一个截距项。支出变量的估计效应是什么?求OLS残差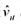 。
。
(ii)lunchit系数的符号在意料之中吗?解释系数的大小。你认为学区的贫穷率对考试通过率有很大的影响吗?
(iii)利用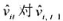 的回归计算AR(1)序列相关的一个检验。你应该在回归中使用1994~1998年的数据。验证存在很强的正序列相关,并讨论为什么。
的回归计算AR(1)序列相关的一个检验。你应该在回归中使用1994~1998年的数据。验证存在很强的正序列相关,并讨论为什么。
(iv)现在用固定效应法估计方程。滞后的支出变量仍显著吗?
(v)你为什么认为在固定效应估计中,注册学生人数和午餐项目变量不是联合显著的?

















