 题目内容
(请给出正确答案)
题目内容
(请给出正确答案)
[单选题]
如果你的数据有许多异常值,那么使用数据的均值与方差去做标准化就不行了,在preprocessing模块中定义了哪个方法可以解决这个问题()。
A.normalizer()
B.robustscale()
C.maxabsscale()
D.scale()
查看答案

 如果结果不匹配,请 联系老师 获取答案
题目内容
(请给出正确答案)
如果结果不匹配,请 联系老师 获取答案
题目内容
(请给出正确答案)
A.normalizer()
B.robustscale()
C.maxabsscale()
D.scale()
如果结果不匹配,请 联系老师 获取答案
 更多“如果你的数据有许多异常值,那么使用数据的均值与方差去做标准化…”相关的问题
更多“如果你的数据有许多异常值,那么使用数据的均值与方差去做标准化…”相关的问题
A.检查异常值是很重要的,因为线性回归对离群效应很敏感
B.线性回归分析要求所有变量特征都必须具有正态分布
C.线性回归假设数据中基本没有多重共线性
D.以上说法都不对
A.数据清单是一片连续的数据区域,不允许出现空行或空列
B.每一列包括相同类型的数据
C.在修改数据清单之前,要确保隐藏的行和列已经被显示。如果清单中的行和列未被显示,那么数据有可能被删除
D.数据清单中的列标可以和数据清单中的其它数据具有相同的格式
(i)你为什么会把这些数据归类为聚类样本?大致上,你预期能从一个典型学生得到大概多少次观测?
(ii)写出一个类似于教材方程(14.12)那样的模型,用到课率和其他特征去解释期终考试成绩。以s作为学生下标和c作为课程下标,对同一个学生哪个变量是不变的?
(iii)如果你把所有的数据混合起来并使用OLS,那么,对影响成绩和到课率的非观测学生特征,你正在做什么假定呢?SAT和学期前GPA在这方面扮演着什么角色呢?
(iv)如果你认为SAT和学期前GPA不足以刻画学生能力,你如何估计到课率对期终考试成绩的影响呢?
参考答案:


6.利用计量经济软件 中的“聚类”选项,便得到教材表14-2中混合OLS估计值充分稳健[即对复合误差(vit:t=1,···,T)中的序列相关和异方差性保持稳健]的标准误为:
中的“聚类”选项,便得到教材表14-2中混合OLS估计值充分稳健[即对复合误差(vit:t=1,···,T)中的序列相关和异方差性保持稳健]的标准误为:
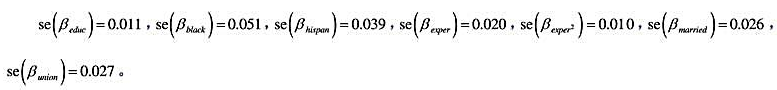
(i)这些标准误与非稳健标准误相比一般如何?为什么?
(ii)混合OLS的稳健标准误与RE的标准误相比如何?解释变量是否随时间变化有什么关系吗?
A.数据有重复现象
B.数据有缺失现象
C.数据不一致或者错误
D.数据之间丢失了关联性
















