

 如果结果不匹配,请
如果结果不匹配,请 
 更多“估计回归参数的方法主要有()和极大似然法、矩估计法。”相关的问题
更多“估计回归参数的方法主要有()和极大似然法、矩估计法。”相关的问题
A.适用于应变量为分类变量时的多因素分析
B.回归系数的假设检验常使用Wald检验
C.常用最小二乘法来估计未知参数
D.xi为无序多分类变量时,若类别数为k,应设置成k-1个哑变量
(i)利用WAGEPRC.RAW中的数据,估计第11章习题5中的分布滞后模型。用回归教材(12.14)来检验AR(1)序列相关。
(ii)用迭代的科克伦-奥卡特方法重新估计这个模型。长期倾向的新估计值是多少?
(iii)用迭代C0求出LRP的标准误。(这要求你估计一个修正方程。)判断LRP估计值在5%的水平上是否统计显著异于1?
用到CONSUMP.RAW中的数据。
(i)在教材例16.7中,用教材15.5节的方法检验在估计教材(16.35)时的那个过度识别约束。你的结论是什么?
(ii)由于潜在的数据度量问题和信息滞后,坎贝尔和曼昆(CampbellandMankiw,1990)使用所有变量的二阶滞后值作为工具变量。只用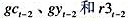 ,作为工具变量重新估计教材(16.35)。这些估计值与教材(16.36)中的那些估计值相比如何?
,作为工具变量重新估计教材(16.35)。这些估计值与教材(16.36)中的那些估计值相比如何?
(iii)将gy,对第(ii)部分的Ⅳ回归,并检验gy,与它们是否充分相关。这一点为什么重要?
A.最大似然估计是使似然函数最大的那个参数作为估计
B.条件中位数估计为先验概率密度的中位数作为估计
C.最小均方估计等于被估计量的条件均值
D.观测数据的获得可以减少待估计参数的不确定性
(i)利用表13-1中同样的变量估计kids的一个泊松回归模型。解释y82的系数。
(ii)保持其他因素不变,黑人妇女和非黑人妇女在生育上的估计百分数差异是多少?
(iii)求σ。有过度散布和散布不足的证据吗?
(iv)计算泊松回归中的拟合值和作为kidsi和kidsi之相关系数平方的R2。并与线性回归模型中的R2相比较。
A.如果使用横断面数据进行回归分析会使r2的值上升。
B.回归分析对估计利息收入不再适用。
C.一些没有包括在模型中的新的因素引起了收入的变化。
D.线性回归分析会提高模型的可信度。















